Microsoft đã trình diễn nghiên cứu mới nhất của mình về AI chuyển văn bản thành giọng nói với một mẫu có tên VALL-E có thể mô phỏng giọng nói của ai đó chỉ từ một mẫu âm thanh dài ba giây, Ars Technica đã báo cáo. Bài phát biểu không chỉ phù hợp với âm sắc mà còn phải phù hợp với cảm xúc của người nói, thậm chí cả âm học của căn phòng. Một ngày nào đó, nó có thể được sử dụng cho các ứng dụng chuyển văn bản thành giọng nói tùy chỉnh hoặc cao cấp, mặc dù giống như deepfakes, nó có nguy cơ bị lạm dụng.
VALL-E là cái mà Microsoft gọi là “mô hình ngôn ngữ codec thần kinh”. Nó bắt nguồn từ Encodec mạng thần kinh nén được hỗ trợ bởi AI của Meta, tạo âm thanh từ đầu vào văn bản và các mẫu ngắn từ người nói mục tiêu.
Trong paper, các nhà nghiên cứu mô tả cách họ đào tạo VALL-E về 60.000 giờ nói tiếng Anh từ hơn 7.000 người nói trên Meta’s LibriLight ) thư viện âm thanh. Giọng nói mà nó cố gắng bắt chước phải gần giống với giọng nói trong dữ liệu huấn luyện. Trong trường hợp đó, nó sẽ sử dụng dữ liệu đào tạo để suy ra âm thanh của người nói mục tiêu nếu nói kiểu nhập văn bản mong muốn. 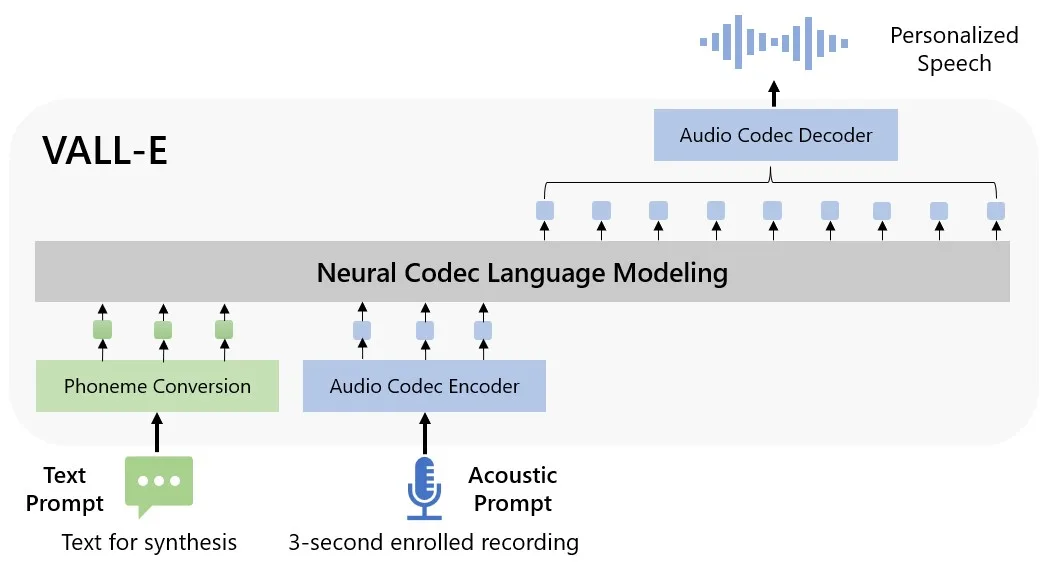
Nhóm cho biết chính xác tính năng này hoạt động tốt như thế nào trên trang VALL-E Github. Đối với mỗi cụm từ họ muốn AI “nói”, họ có lời nhắc ba giây từ người nói để bắt chước, “sự thật cơ bản” của cùng một người nói đang nói một cụm từ khác để so sánh, chuyển văn bản thành giọng nói thông thường “cơ sở”. tổng hợp và mẫu VALL-E ở cuối.
Kết quả lẫn lộn, với một số âm thanh giống như máy móc và một số khác thực tế đến kinh ngạc. Thực tế là nó vẫn giữ được giai điệu cảm xúc của các mẫu ban đầu là thứ bán được những mẫu hoạt động. Nó cũng phù hợp với môi trường âm thanh một cách trung thực, vì vậy nếu người nói ghi lại giọng nói của họ trong hội trường có tiếng vang, thì đầu ra của VALL-E cũng giống như phát ra từ cùng một nơi.
Để cải thiện mô hình, Microsoft có kế hoạch mở rộng quy mô dữ liệu đào tạo của mình “để cải thiện hiệu suất của mô hình trên các quan điểm về tiến trình, phong cách nói và sự tương đồng của người nói.” Nó cũng đang khám phá các cách để giảm bớt những từ không rõ ràng hoặc bị bỏ sót.
Microsoft đã quyết định không tạo mã nguồn mở, có thể do những rủi ro vốn có với AI có thể đưa các từ vào miệng của ai đó. Nó nói thêm rằng nó sẽ tuân theo “Nguyên tắc AI của Microsoft” trong bất kỳ sự phát triển nào nữa. “Vì VALL-E có thể tổng hợp giọng nói để duy trì danh tính của người nói, nên nó có thể tiềm ẩn rủi ro khi sử dụng sai mô hình, chẳng hạn như giả mạo nhận dạng giọng nói hoặc mạo danh”, công ty viết trong phần “Tác động rộng hơn” trong kết luận của mình.
Tất cả các sản phẩm do Engadget đề xuất đều do nhóm biên tập của chúng tôi lựa chọn, độc lập với công ty mẹ của chúng tôi. Một số câu chuyện của chúng tôi bao gồm các liên kết liên kết. Nếu bạn mua thứ gì đó thông qua một trong những liên kết này, chúng tôi có thể kiếm được hoa hồng liên kết. Tất cả giá đều chính xác tại thời điểm xuất bản.
Sưu tầm

{kind=link}